Table of Contents
- Introduction
- Kernel-mode Rootkits
- Common Rootkit Functionality
- Rootkit Detection Methodology
- Detected Rootkits
Introduction
Loadable kernel modules, LKMs for short, are an integral companion to the Linux kernel. Typically, LKMs are used to add support for new hardware (as device drivers) or file systems or add additional system calls. Without LKMs, an operating system would have to include all possible anticipated functionality. This is borderline impossible to do when developing a platform to be used with everything from a smartphone to a server. LKMs provide additional functionality to the kernel, and by extension the user of the computer, and can be safely added or removed when they are needed or not needed. Unfortunately, this functionality can be abused to create malware, namely kernel-mode rootkits. Linux kernel-mode rootkits are significantly more difficult to detect than most other malware when performed properly as the functionality they provide exposes a flawed trust model a user has in the information that his or her system returns. Therefore, developing multiple methods of detection on more advanced rootkits would benefit system administrators globally.
Kernel-mode Rootkits
Let's explore why a malware author would want to develop a rootkit that lives inside the kernel. Rootkits can either be in user-land or kernel-land. Figure 1 details the theoretical privilege rings associated with user-land and kernel-land. User-land refers to privilege ring 3, while kernel-land refers to privilege ring 0. The kernel is responsible for handling a lot of the user’s system’s functionality whether that be browsing local files or using a web browser to browse the Internet. This is done through the implementation of system calls - low-level functions that run in a kernel context.

For example, a library function like printf eventually always calls write to write whatever information to whatever peripheral you're sending it to. You might be asking now, "but if write is inside the kernel, how does my input get inside the kernel to run the code?" Without diving into the Interrupt Descriptor Table here, there exists an assembly instruction int 0x80. In assembly, when a syscall is set to execute, this instruction is emitted from the compiler. This instruction int 0x80 triggers a maskable interrupt which transfers control from the user to the kernel (ring 3 to ring 0). For completeness I will mention that this is no longer the standard way of doing it (SYSENTER/SYSEXIT and SYSCALL exist now) but the concept is the same; the user is expecting the kernel to handle this call and return the correct results. When rootkits become part of the kernel, they are able to modify on-the-fly what information the user receives.
Common Rootkit Functionality
Rootkits often have core functionality that make them similar. The most common rootkit functions involve hiding the attacker’s malicious files, processes, or network connections, providing unauthorized access for future events (backdoors), deploying keyloggers, and deleting system logs that would reveal the attacker’s presence. In the next section, we’ll discuss the implementation-specific details that designing kernel-module rootkit functions entail.
Rootkit Detection Methodology
This section will detail how Tyton attempts to uncover kernel-mode rootkits.
Hidden Modules
Sysfs contains a multitude of ksets or kernel sets which in turn contain multiple kernel objects or kobjects. The kset module_kset within sysfs holds kobject references to all loaded kernel modules. By traversing this list, we can resolve each kobject back to its containing object (its referenced kernel module). When compared with the current module list entries from find_module(kobj->mod->name)), we can uncover modules who unlinked themselves from the list. For more detail on the relationship between ksets and kobjects, see Fig. 2.

The following code is how Tyton iterates over each kobject and determines if the module is trying to hide or not.
list_for_each_entry_safe(cur, tmp, &mod_kset->list, entry){
if (!kobject_name(tmp))
break;
kobj = container_of(tmp, struct module_kobject, kobj);
if (kobj && kobj->mod && kobj->mod->name){
mutex_lock(&module_mutex);
if(!find_module(kobj->mod->name))
ALERT("Module [%s] hidden.\n", kobj->mod->name);
mutex_unlock(&module_mutex);
}
}
Syscall/Interrupt Descriptor Table Hooking
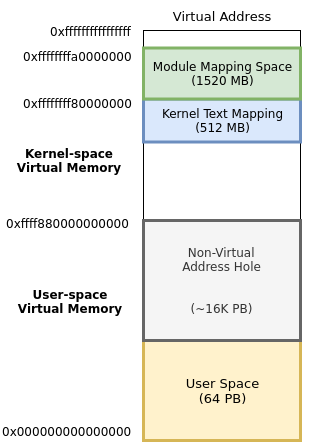
Tyton searches through the syscall table to see if any functions point outside the core kernel text section. If they do not point within the core kernel text section, it is likely that they have been hooked but to make sure we search all loaded modules to verify this. Figure 3 depicts the spec of the kernel memory map for x86_64. You can find it here. We can see here that the kernel text mapping resides in its own region and kernel modules are mapped into the space directly above them. Using this, we can determine where the function address resides and make a judgement call on whether or not it has been hooked.
The code that the kernel uses to check if an address resides within this text mapping is below. _stext and _etext refer to the start of the text mapping and the end respectively. You can find it here.
int notrace
core_kernel_text(unsigned long addr)
{
if (addr >= (unsigned long)_stext && addr < (unsigned long)_etext)
return 1;
if (system_state < SYSTEM_RUNNING && init_kernel_text(addr))
return 1;
return 0;
}
Tyton iterates over the syscall table and leverages this function to verify the integrity of the syscall table. sct[i] indicates the i'th syscall. get_module_from_addr attempts to retrieve the kernel module associated with the hook. If that returns NULL, then the module is hidden. In that case, we use an alternative method to resolve hidden modules.
for (i = 0; i < NR_syscalls; i++){
addr = sct[i];
if (!ckt(addr)){
mutex_lock(&module_mutex);
mod = get_module_from_addr(addr);
if (mod){
ALERT("Module [%s] hooked syscall [%d].\n", mod->name, i);
} else {
mod_name = find_hidden_module(addr);
if (mod_name)
ALERT("Hidden module [%s] hooked syscall [%d].\n", mod_name, i);
}
mutex_unlock(&module_mutex);
}
}
Netfilter Hooking
Tyton searches through all possible Netfilter hook combinations and reports all modules that have active Netfilter hooks. Netfilter hooks have a legitimate use, but it is unlikely that they would be present beyond those made for iptables, ebtables, and friends. They are commonly used in kernel-mode rootkits to create backdoors by intercepting packets used to authenticate for port knocking. If you'd like to learn more about implementing Netfilter hooks in your kernel, you can find that information here.
The code involved is quite cumbersome as Netfilter functions have been changed quite frequently recently. Another problem with accessing this information is that there is no friendly API for it. For example, all three of the following code blocks perform the same action - iterating over an array of netfilter hooks.
For kernel versions ≥ 4.14, we can steal the nf_hook_entry_head function as future functions rely on the same prototype with it returning a struct nf_hook_entries up through 4.19 (so far).
static struct nf_hook_entries __rcu **
nf_hook_entry_head(struct net *net, int pf, unsigned int hooknum, struct net_device *dev)
{
if (pf != NFPROTO_NETDEV)
return net->nf.hooks[pf]+hooknum;
if (hooknum == NF_NETDEV_INGRESS){
if (dev && dev_net(dev) == net)
return &dev->nf_hooks_ingress;
}
return NULL;
}
int
analyze_netfilter(void)
{
int i, j;
struct nf_hook_entries *p;
struct nf_hook_entries __rcu **pp;
for (i = 0; i < NFPROTO_NUMPROTO; i++){
for (j = 0; j < NF_MAX_HOOKS; j++){
pp = nf_hook_entry_head(&init_net, i, j, NULL);
if (!pp)
return -EINVAL;
p = nf_entry_dereference(*pp);
if (!p)
continue;
search_hooks(p);
}
}
return 0;
}
For kernel versions < 4.14, we don't have struct nf_hook_entries. We have to use the kernel's built-in list mechanism, struct list_head. This means that our differences won't stop at simply iterating over the netfilter hooks, but continue into how we can access ther data.
static struct list_head *
nf_find_hook_list(struct net *net, int pf, unsigned int hooknum, struct net_device *dev)
{
if (pf != NFPROTO_NETDEV)
return &net->nf.hooks[pf][hooknum];
if (hooknum == NF_NETDEV_INGRESS){
if (dev && dev_net(dev) == net)
return &dev->nf_hooks_ingress;
}
return NULL;
}
int
analyze_netfilter(void)
{
int i, j;
for (i = 0; i < NFPROTO_NUMPROTO; i++){
for (j = 0; j < NF_MAX_HOOKS; j++){
search_hooks(nf_find_hook_list(&init_net, i, j, NULL));
}
}
return 0;
}
Now we still have two access them, which requires even more kernel version-specific code. Such is the cost of supporting multiple kernel versions.
For ≥ 4.14, we need to iterate over a struct nf_hook_entries *. This is simple as inside that struct is an integer called num_hook_entries. We can then use the hooks array inside the same structure to grab every hook's address and check it against the kernel text mapping.
static void
search_hooks(const struct nf_hook_entries *e)
{
int i;
const char *mod_name;
unsigned long addr;
struct module *mod;
for (i = 0; i < e->num_hook_entries; i++){
addr = (unsigned long)e->hooks[i].hook;
mutex_lock(&module_mutex);
mod = get_module_from_addr(addr);
if (mod){
ALERT("Module [%s] controls a Netfilter hook.\n", mod->name);
} else {
mod_name = find_hidden_module(addr);
ALERT("Module [%s] controls a Netfilter hook.\n", mod_name);
}
mutex_unlock(&module_mutex);
}
}
For < 4.14, we need to iterate over a kernel list. This is done with list_for_each_entry or list_for_each_entry_safe.
static void
search_hooks(const struct list_head *hook_list)
{
const char *mod_name;
unsigned long addr;
struct module *mod;
struct nf_hook_ops *elem;
list_for_each_entry(elem, hook_list, list){
addr = (unsigned long)elem->hook;
mutex_lock(&module_mutex);
mod = get_module_from_addr(addr);
if (mod){
ALERT("Module [%s] controls a Netfilter hook.\n", mod->name);
} else {
mod_name = find_hidden_module(addr);
ALERT("Module [%s] controls a Netfilter hook.\n", mod_name);
}
mutex_unlock(&module_mutex);
}
}
Network Protocol Hooking
Tyton grabs the init_net.proc_net process directory entry (on your filesystem this is equivalent to /proc/net/) and iterates over every subdirectory in the red-black tree looking for subdirectories named tcp, tcp6, udp, udp6, udplite, and udplite6. Once we've acquired the directory entry for the specific network protocol, we can grab the function pointers for seq_fops and seq_ops - namely we are looking for seq_fops->llseek, seq_fops->read, seq_fops->release, and seq_ops->show. In doing this, we can verify that the operation function pointers of network protocols are still inside the core kernel text section and not being manipulated by a kernel module. These are commonly hooked to hide network traffic or exposed ports from netstat and other user-land interfaces.
To iterate over multiple interfaces and check the same operations, I devised a simple struct called net_entry. This struct holds the name of the entry we're searching for, and once found, the /proc directory entry.
struct net_entry {
const char *name;
struct proc_dir_entry *entry;
};
struct net_entry net[NUM_NET_ENTRIES] = {
{"tcp", NULL},
{"tcp6", NULL},
{"udp", NULL},
{"udp6", NULL},
{"udplite", NULL},
{"udplite6", NULL}
};
The following code iterates over a red-black tree (in our case the rb-tree of /proc/net) and searches for an entry with the name of the target string. We can use this to find our target net entries and assign the corresponding struct proc_dir_entry.
struct proc_dir_entry *
find_subdir(struct rb_root *tree, const char *str)
{
struct rb_node *node = rb_first(tree);
struct proc_dir_entry *e = NULL;
while (node){
e = rb_entry(node, struct proc_dir_entry, subdir_node);
if (strcmp(e->name, str) == 0)
return e;
node = rb_next(node);
}
return NULL;
}
We can now iterate over every net entry and grab their seq_ops and seq_fops.
unsigned long op_addr[4];
const struct seq_operations *seq_ops;
const struct file_operations *seq_fops;
const char *mod_name, *op_string[4] = {
"llseek", "read", "release", "show"
};
for (i = 0; i < NUM_NET_ENTRIES; i++){
net[i].entry = find_subdir(&init_net.proc_net->subdir, net[i].name);
if (!net[i].entry)
continue;
seq_ops = net[i].entry->seq_ops;
seq_fops = net[i].entry->proc_fops;
op_addr[0] = *(unsigned long *)seq_fops->llseek;
op_addr[1] = *(unsigned long *)seq_fops->read;
op_addr[2] = *(unsigned long *)seq_fops->release;
op_addr[3] = *(unsigned long *)seq_ops->show;
/* Code to check if all of op_addr is in kernel text mapping */
}
Process File Operations Hooking
Tyton opens the /proc file pointer and check to see if any file operations (namely iterate) point outside the core kernel text section. This file pointer can be hooked by a rootkit to hide malicious processes by checking each directory entry against a list of processes that it intends to hide. If it finds one, it can simply skip over the directory entry as if it was never there resulting in it not being reported back to the user.
The following code creates a file pointer to /proc and checks to see if iterate or readdir have been hooked by a module.
fp = filp_open("/proc", O_RDONLY, S_IRUSR);
#if LINUX_VERSION_CODE >= KERNEL_VERSION(3,11,0)
addr = (unsigned long)fp->f_op->iterate;
#else
addr = (unsigned long)fp->f_op->readdir;
#endif
if (!ckt(addr)){
mod = get_module_from_addr(addr);
if (mod){
ALERT("Module [%s] hijacked /proc fops.\n", mod->name);
} ...
}
Zeroed Process Inodes
Tyton searches through /proc for all linux_dirent structures and examine the inodes to find any set to zero. An inode of zero is typically ignored from directory listings which makes it a good candidate for rootkits to set directories to in order to hide their files.
The following code iterates over a linux_dirent structure, essentially a 1-D array, to find any directory entries with an inode of 0. What isn't pictured is a custom filldir function that is necessary to fill the linux_dirent structure. This, while challenging/annoying, is not important to understanding the detection.
while (size > 0){
if (d->d_ino == 0){
buffer = kzalloc(d->d_namlen+1, GFP_KERNEL);
memcpy(buffer, d->d_name, d->d_namlen);
ALERT("Hidden Process [/proc/%s].\n", buffer);
kfree(buffer);
}
reclen = ALIGN(sizeof(*d) + d->d_namlen, sizeof(u64));
d = (struct linux_dirent *)((char *)d + reclen);
size -= reclen;
}
Detected Rootkits
Below is a table of rootkits and whether or not Tyton can detect them based on currently implemented features. Common features are those that you will commonly find in even the most basic kernel-mode rootkits. Advanced features are those that provide increased evasion features but are somewhat challenging or uncommon to implement.
- Found
- The rootkit has implemented this feature and it has been found.
- Evaded
- The rootkit has implemented this feature and it has not been found.
- N/a
- The rootkit has not implemented this feature.
Common Features
| Rootkit | Hidden Module | SCT/IDT Hooking | Netfilter Hooking |
|---|---|---|---|
| Reptile | Found | Evaded | Found |
| Diamorphine | Found | Found | Found |
Advanced Features
| Rootkit | Network Hooking | Zeroed Inodes | Proc Hooking |
|---|---|---|---|
| Reptile | N/a | N/a | N/a |
| Diamorphine | N/a | N/a | N/a |